xAI 近日低调发布了 Grok 4.3 模型,没有大规模宣传造势,甚至马斯克也未在社交平台单独发文提及。这款被外界视为过渡版本的新模型,却凭借务实升级策略引发关注,在价格、速度和工具实用性方面展现出独特竞争力。
在核心性能上,Grok 4.3 的 Intelligence Index 评分达到 53 分,较前代提升 4 分,超越 Claude Sonnet 4.6 和 Muse Spark 等竞品。在代理任务测试平台 GDPval-AA 上,其表现尤为突出,以 1500 Elo 的成绩较前代提升 321 分,展现出在资料整理、复杂流程执行等场景的显著进步。用户可借助该模型完成周报撰写、表格搭建、方案策划等办公任务,甚至能在一个计算环境中完成代码编写、运行和文件生成的全流程操作。
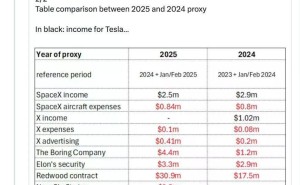
价格策略成为 Grok 4.3 的核心优势。其 API 定价降至每百万输入 Tokens 1.25 美元、输出 Tokens 2.50 美元,输入成本降低约 40%,输出成本降低约 60%。根据 Artificial Analysis 测算,运行整套 Intelligence Index 评测的成本较前代下降约 20%。这种价格调整不仅直接影响开发者成本,更会通过基于 API 构建的消费级产品间接惠及普通用户。
速度表现呈现双面性。该模型输出速度达 196 Tokens/s,在长文本生成场景中优势明显,但首 Token 延迟较高的问题在短对话场景中较为突出。这种"先思考后输出"的特性,使得用户在处理复杂任务时能感受到效率提升,而在简单交互中可能因等待产生体验落差。
在交互体验方面,Grok 4.3 延续了前代在语气自然度上的优势。基于 X 平台海量口语数据训练的特性,使其在文本语气把握、正式程度控制等方面表现突出,特别适合消息撰写、口语转写等场景。Hacker News 用户反馈显示,非英语母语者普遍认为该模型在人际表达微妙度的处理上更接近真人。
尽管在实用场景取得突破,Grok 4.3 仍与顶级模型存在差距。其 Intelligence Index 评分落后 GPT-5.5 7 分,在复杂推理、代码调试等专业场景的稳定性不足。在幻觉控制方面,虽然知识覆盖率提升 8 分,但非幻觉率下降 8 分,意味着模型更易产生自信但错误的回答,这在医疗、法律等高风险领域构成使用隐患。
功能扩展方面,Grok 4.3 支持 100 万 Token 上下文窗口,可处理长文档、代码库等复杂信息,并强化了工具调用、网页搜索、代码执行等能力。配套推出的 Custom Voices、语音代理等产品,推动模型向多模态交互发展。但消费级市场的竞争逻辑表明,功能丰富性需与可靠性平衡,用户最终关注的是等待时间、错误率和操作便捷性等核心指标。
这款新模型的定位逐渐清晰:它不是追求技术巅峰的实验室产品,而是面向成本敏感型用户的工作助手。对于需要快速生成初稿、处理日常办公任务的场景,Grok 4.3 凭借价格和速度优势形成差异化竞争力;但在涉及专业判断、事实核查的高价值任务中,GPT-5.5 和 Claude Opus 4.7 仍是更稳妥的选择。xAI 通过这次升级证明,在AI技术竞赛中,务实的产品策略同样能赢得市场认可。