“全球大模型第一股”智谱(02513.HK)今日正式推出开源模型GLM-5.1,官方宣称其为当前最智能的模型。该模型于今日凌晨在海外市场率先发布,延续了GLM-5的论文技术框架,并在预训练阶段引入DeepSeek Sparse Attention(DSA)技术,通过动态稀疏注意力机制将长上下文注意力计算效率提升1.5至2倍。
GLM-5.1专为AI智能体设计,拥有7440亿参数和400亿激活参数,支持零人工介入的独立运行模式,可持续工作超过8小时。其核心突破在于能够从零开始完成一套完整的Linux桌面系统开发,这一成果相当于传统4人开发团队一周的工作量。在编码性能方面,该模型在Agent Coding SWE-Bench Pro测试中取得58.4分,超越GPT-5.4和Claude Opus 4.6,三项编码基准综合排名全球前三、国内开源领域第一。
智谱联合创始人唐杰指出,GLM-5.1重点强化长时任务处理能力,新增长时程任务(LHT)功能模块,聚焦记忆管理、持续学习与自我反思三大核心领域。技术团队通过优化模型架构,使其在处理复杂任务时具备更强的上下文关联能力和自适应进化能力。
在商业策略层面,智谱展现出与行业趋势截然不同的定价逻辑。当多数企业通过降价争夺市场份额时,GLM-5.1却将编码场景定价上调10%,输入价格达每百万token1.4美元,输出价格升至4.4美元,首次与海外头部厂商Anthropic持平。公司同步推出差异化计费方案:高峰时段(北京时间14:00-18:00)消耗3倍配额,非高峰时段消耗2倍配额,但4月底前非高峰时段按1倍计费。该模型已面向所有Coding Plan用户开放,用户可根据需求灵活选择使用时段。
智谱CEO张鹏在对话中坦言中美AI差距:“当前中国大模型落后美国6至12个月,这种差距源于两个创新生态体系的本质差异。我们既要弥补技术债务,又要兼顾社会需求,这种双重压力迫使我们必须走出具有自身特色的创新道路。”他特别强调,公司终极目标是打造全自治智能体,实现7×24小时无间断的任务感知、目标分解、执行交付与自我进化。
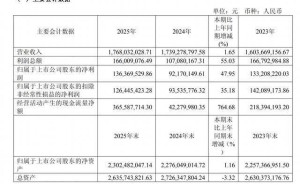
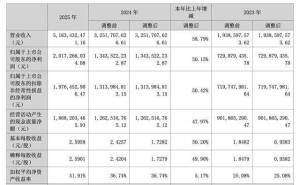
财务数据显示,智谱2024年营收达7.24亿元人民币(约1.048亿美元),同比增长132%,但总亏损扩大至47.2亿元,毛利率从56.3%下滑至41%。尽管如此,其股价自1月IPO以来累计涨幅近600%,市值一度突破4000亿港元。市场分析认为,这种“亏损扩张”模式反映出资本市场对其技术潜力的认可。
在战略布局方面,智谱正将竞争焦点从OpenAI转向Anthropic。张鹏透露,公司设立的X-Lab创业研究部门专注于前沿技术探索,包括神经网络优化、软硬件融合等领域,其技术体系更具灵活性。该部门由年轻科研人员组成,不受传统研发路径约束,可自由选择研究方向。“我们容忍失败,因为想象力是这个时代最珍贵的财富。”张鹏如此评价这个创新试验田。