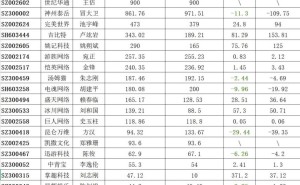
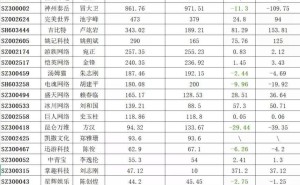
在Cisco Live EMEA活动期间,思科通用硬件事业部执行副总裁Martin Lund向外界详细介绍了其最新发布的Silicon One G300网络芯片。这款基于台积电3纳米工艺打造的102.4Tbps芯片,标志着AI数据中心基础设施领域迎来重大突破。作为当前全球仅有的三款具备该性能水平的网络芯片之一,G300与英伟达、博通的产品形成直接竞争,为连接大规模GPU集群提供了前所未有的网络容量。
G300的核心优势体现在其可编程架构设计上。与传统固定功能芯片不同,该芯片支持部署后的动态重新配置,能够根据AI工作负载的演进实时调整网络参数。这种灵活性对于处理快速变化的AI训练任务至关重要——网络运营商无需更换硬件即可实现协议更新或负载均衡优化。据Lund透露,在超大规模AI工厂中部署10万颗G300芯片时,这种可编程特性可带来显著的运营成本节约和设备生命周期延长。
在性能指标方面,G300通过64个1.6Tb以太网端口实现总交换容量翻倍,较前代G200提升100%。其带宽密度达到近25年前10Gb标准的1万倍,逼近当前半导体制造的物理极限。这种极致性能带来新的工程挑战:芯片产生的热量必须通过液冷系统才能有效散发,预示着交换设备领域将全面进入液冷时代。
关于AI网络标准之争,Lund明确表示以太网已取得决定性胜利。尽管InfiniBand在特定场景下具有低延迟优势,但其65,000个节点的地址空间限制无法满足百万级计算节点的扩展需求。相比之下,以太网凭借成熟的生态系统、互操作性和地址容量,成为连接多样化AI硬件的理想选择。这种技术路线选择正推动AI计算架构向解耦方向发展,不同厂商的处理器和加速器可通过统一网络结构互联。
在客户采用方面,全球六大超大规模云厂商中已有五家部署了Silicon One技术,第六家合作正在推进中。新型云服务提供商和企业专用AI工厂构成新的增长市场,这些部署虽然GPU规模从数千到数十万不等,但都需要G300提供的交换能力。Lund强调,思科的技术下沉策略正在发挥作用——G300的1.6Tb端口技术未来将逐步应用于运营商和企业级设备。
对于光子技术发展,Lund预测共封装光学(CPO)将成为首个突破点。通过将光学引擎集成在距离网络芯片极近的位置,这种设计可降低70%的电光转换功耗。但真正实现光域分组交换仍需数年时间,当前光交换技术受限于反射镜重构速度,无法满足逐包交换需求。他甚至认为,在全光交换实用化之前,量子计算可能率先取得突破。
在可靠性挑战方面,光子系统面临激光器寿命和故障点增加等问题。思科提出的解决方案是采用外部可插拔激光器设计,允许在不停机的情况下更换光源模块。这种设计思路类似于服务器电源的热插拔功能,有效平衡了能效优势与维护需求。随着网络带宽持续翻倍,铜缆传输距离不断缩短的物理限制,正在加速光连接技术的普及进程。
思科的垂直整合战略贯穿整个产品体系。从芯片设计到硬件制造,从软件平台到安全架构,该公司构建了完整的技术栈。这种模式与苹果的生态策略相似,但区别在于思科将解决方案开放给全球客户,而非仅供内部使用。Silicon One架构作为核心基础,通过可扩展的指令集支持从园区网络到超大规模AI基础设施的多样化需求,这种设计哲学正在重塑网络设备行业的竞争格局。