华为在2025年的鲲鹏昇腾开发者大会上,正式揭晓了其最新的技术创新——昇腾超节点技术。这一技术不仅实现了业界前所未有的384卡高速总线互联规模,更为AI大模型的未来发展开辟了新路径。
当前,AI大模型的发展正处于参数规模与运行效率交替提升的关键阶段。一方面,Scaling Law持续推动模型能力的边界拓展;另一方面,诸如DeepSeek等创新架构与技术,正加快模型在各行各业的落地应用步伐。在此背景下,MoE模型结构逐渐成为主流,但其复杂的混合并行策略给计算带来了巨大挑战,单次通信量高达GB级别且难以通过技术手段掩盖。
随着模型并行规模的日益扩大,传统服务器跨机带宽的限制愈发凸显,成为制约训练效率的关键因素。传统服务器主要依赖以太网络实现跨机互联,通信带宽有限。实践表明,当分布式策略的混合并行域超过8卡时,跨机通信带宽便成为明显的性能瓶颈,导致整体性能显著下滑。
为了突破这一瓶颈,华为推出了昇腾超节点技术。该技术打破了传统的以CPU为中心的冯诺依曼架构,创新性地提出了对等计算架构。通过高速总线互联技术,华为成功将总线从服务器内部扩展至整机柜乃至跨机柜,实现了通信性能的重大飞跃。在超节点范围内,高速总线互联替代了传统的以太网,通信带宽提升了15倍,单跳通信时延从2微秒降低至200纳秒,降幅达10倍。这一变革使得集群内的各节点能够像一台计算机一样协同工作,从而有效突破了系统性能的限制。
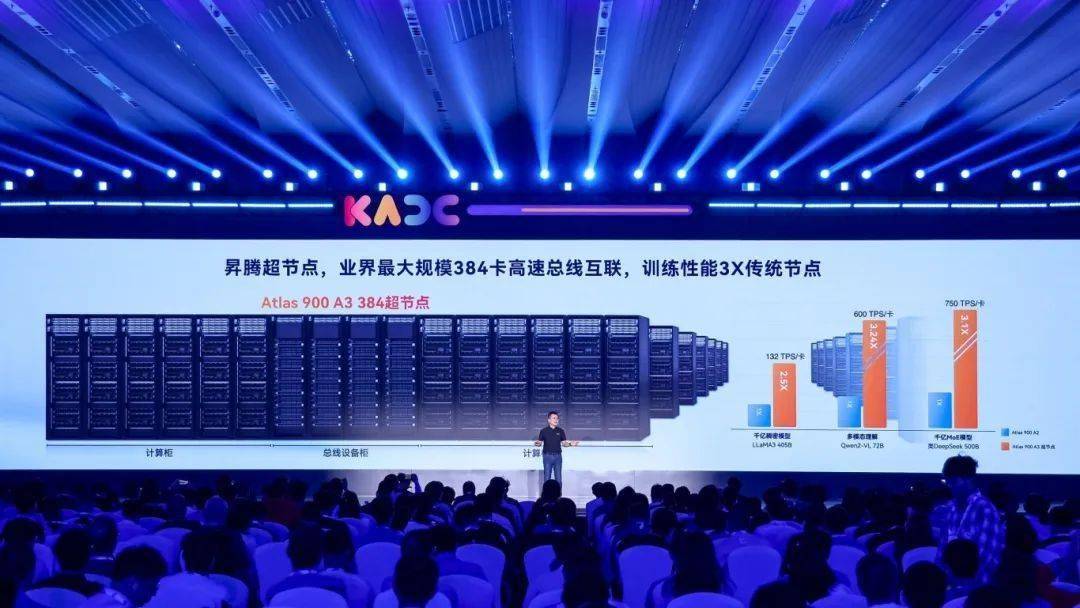
据悉,此次推出的昇腾384超节点由12个计算柜和4个总线柜组成,是当前业界规模最大的超节点。依托华为在ICT领域的深厚积累与卓越技术实力,该超节点通过最佳负载均衡组网方案,可进一步扩展为包含数万卡的Atlas 900 SuperCluster超节点集群,为未来更大规模模型的演进提供了坚实支撑。
性能测试数据显示,在昇腾超节点集群上运行LLaMA 3等千亿级稠密模型时,性能相比传统集群提升了2.5倍以上。而在通信需求更高的Qwen、DeepSeek等多模态、MoE模型上,性能提升更是达到了3倍以上,相较于业界其他集群,性能高出1.2倍,彰显了华为昇腾超节点在AI计算领域的领先地位。