英伟达公司近期公布了一项重大技术突破,一款名为Parakeet TDT 0.6B的先进自动语音识别(ASR)模型已在Hugging Face平台上全面开放源代码。据行业内部消息透露,这款新模型在语音处理速度和转录准确性方面均达到了前所未有的水平。
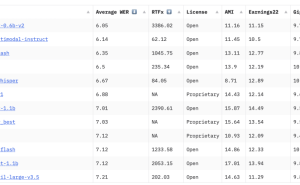
Parakeet TDT 0.6B的亮点之一在于其卓越的处理效率。该模型能够在短短1秒内完成长达60分钟的音频文件处理,这一速度是当前主流开源ASR模型的50倍之多。在Hugging Face的Open ASR排行榜上,Parakeet TDT 0.6B的字错率仅为6.05%,在同类开源模型中表现优异。这一性能使得该模型在实时语音转录、语音内容分析、呼叫中心智能化以及音视频内容索引等多个企业级应用场景中极具竞争力。
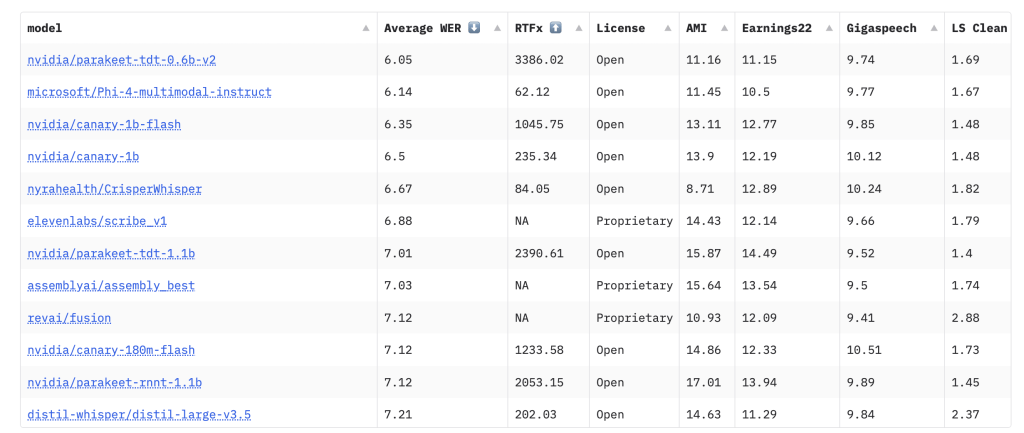
技术层面,Parakeet TDT 0.6B采用了Transformer架构,并经过高质量的转录数据训练与微调。同时,该模型在英伟达硬件平台上进行了深度优化,以实现更高的运算效率。其技术特点包括6亿参数的编码-解码结构、支持量化与融合内核以提升计算性能、采用TDT(Transducer Decoder Transformer)架构,以及具备精确的时间戳、数字格式化和标点恢复能力。
尤为Parakeet TDT 0.6B首次实现了对歌曲内容的歌词转录功能,这一功能在同类模型中极为罕见。通过结合英伟达的TensorRT和FP8量化技术,该模型在实际运行中的实时率(RTF)高达3386,展现出强大的实时处理能力。这一特性为音乐内容索引和媒体平台提供了新的应用场景和可能性。
除了高效的处理速度和准确的识别能力外,Parakeet TDT 0.6B还集成了多项实用功能。例如,它能够将歌曲音频转化为歌词文本,适用于音乐和媒体行业的多种需求;支持数字与时间戳的格式化输出,极大提升了会议记录、法律文档和医疗报告等内容的可读性;而标点恢复功能则有助于后续自然语言处理(NLP)任务的顺利进行。这些附加功能不仅提高了语音转文字的整体质量,还减少了后期编辑和人工干预的需求,使得该模型特别适合大规模的企业级应用。