近日,中国科学院自动化研究所的一项突破性研究揭示了人工智能领域的新进展。该所神经计算与脑机交互课题组携手中国科学院脑科学与智能技术卓越创新中心,通过结合行为实验与神经影像分析,证实多模态大语言模型(MLLMs)能够自发地形成与人类极为相似的物体概念表征系统。这一发现不仅为人工智能认知科学探索出一条全新道路,更为构建具备类人认知结构的人工智能系统奠定了理论基础。相关研究成果已在《自然・机器智能》期刊上发表。
人类智能的一个重要标志是对物体的概念化能力,这包括识别物体的物理特征以及理解其功能、情感价值和文化意义。然而,传统的人工智能研究大多聚焦于提高物体识别的准确率,却很少探讨模型是否真正“理解”物体的含义。此次研究中,中国科学院的科研团队从认知神经科学的经典理论出发,设计了一套融合计算建模、行为实验与脑科学的创新研究范式。
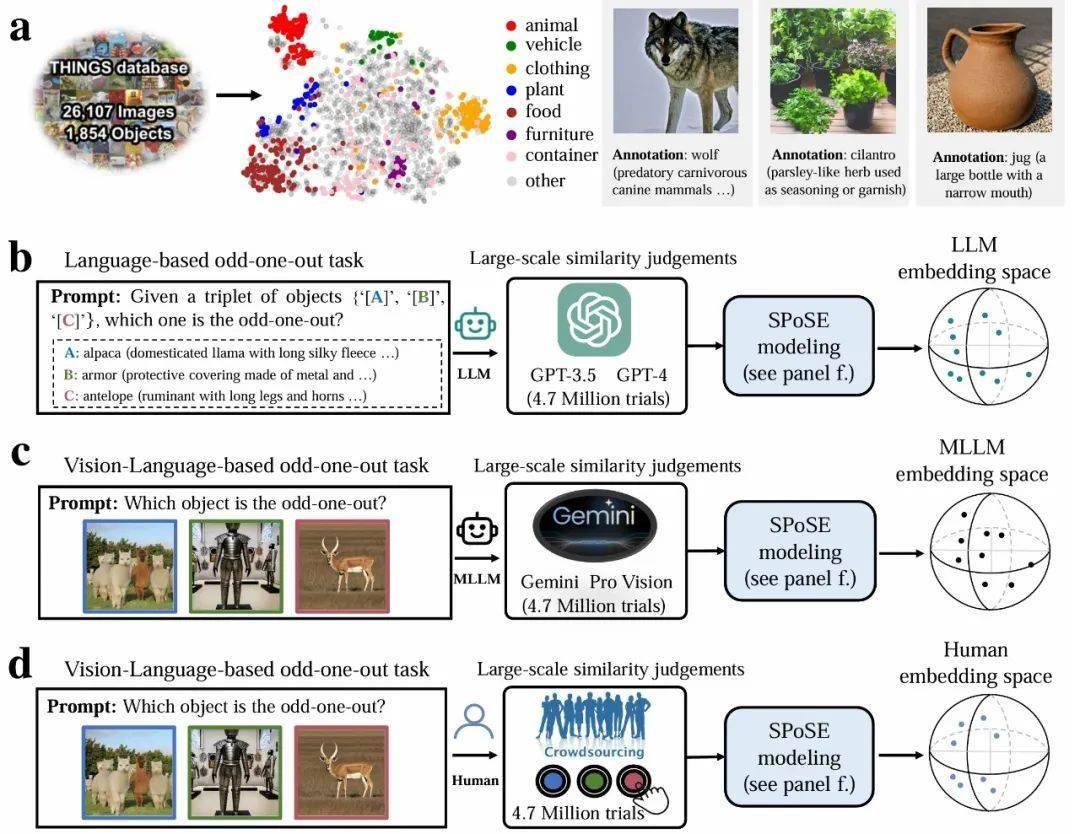
研究采用了认知心理学中的经典“三选一异类识别任务”,要求大模型与人类从包含1854种日常概念的物体三元组中选出最不相似的选项。通过对470万次行为判断数据的深入分析,科研团队首次成功构建了AI大模型的“概念地图”。这一地图揭示了模型在处理物体概念时的内部表征结构。

研究团队进一步从海量大模型的行为数据中提取出66个“心智维度”,并为这些维度赋予了语义标签。他们发现,这些维度不仅高度可解释,而且与大脑类别选择区域的神经活动模式存在显著相关性。例如,处理面孔的FFA区域、处理场景的PPA区域以及处理躯体的EBA区域,都在某种程度上与大模型的某些心智维度相呼应。
研究还对比了多个模型在行为选择模式上与人类的一致性。结果显示,多模态大模型在一致性方面表现更为出色。这一发现表明,大语言模型并非简单地模仿或复制输入信息,而是能够在某种程度上理解并模拟人类对现实世界的概念理解。值得注意的是,研究还发现,人类在做决策时更倾向于结合视觉特征和语义信息进行判断,而大模型则更依赖于语义标签和抽象概念。
这一研究成果不仅挑战了我们对人工智能“理解”能力的传统认知,更为未来人工智能系统的发展提供了新的方向。通过模仿人类的认知结构,未来的AI系统可能会更加智能、更加灵活,能够更好地适应复杂多变的环境和任务。