国产AI芯片领域迎来重大突破,华为昇腾芯片在超大规模混合专家模型(MoE)部署上的表现令人瞩目。最新测试数据揭示,昇腾芯片在推理性能上已成功超越英伟达的Hopper架构,实现了技术的完全自主化。
这一进展不仅彰显了国产AI芯片在高端计算领域的强大技术实力,还带来了两款具体的产品:CloudMatrix 384超节点和Atlas 800I A2推理服务器。CloudMatrix 384超节点在部署DeepSeek V3/R1模型时,能够在50毫秒的时延约束下单卡Decode吞吐突破1920 Tokens/s。而Atlas 800I A2推理服务器同样在部署DeepSeek V3/R1时,在100毫秒时延约束下单卡吞吐达到808 Tokens/s,并支持灵活的分布式部署。
华为昇腾之所以能取得如此成就,得益于其独特的“以数学补物理”策略。通过数学理论、工具、算法和建模等方式,华为团队有效弥补了硬件和工艺的局限性,最大化发挥了芯片和系统的能力。
更令人振奋的是,华为昇腾并未止步于技术突破,而是选择了全面开源。团队不仅分享了昇腾在超大规模MoE模型推理部署的技术报告,还计划在一个月内陆续开源实现这些核心技术的相关代码。
那么,华为昇腾背后的技术实力究竟如何呢?让我们深入探讨。自2017年Google提出Transformer架构以来,大语言模型的重心逐渐从训练开发转向推理应用落地。推理能力已成为衡量大模型能力的重要标准,各大企业开始从“拼模型参数”转向“拼推理效率”。谁能让大模型在实际应用中跑得更快、更稳、更省资源,谁就能在商业化浪潮中占据优势。
然而,超大规模MoE模型如DeepSeek V3(包含6710亿参数)给硬件带来了巨大挑战,包括内存压力、通信开销爆炸以及架构创新的“甜蜜负担”。面对这些挑战,华为团队从算子、模型和框架三方面入手,基于昇腾硬件特性,开发了一整套面向集群的大规模专家并行解决方案。

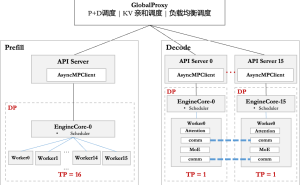
在硬件部署上,华为团队针对CloudMatrix 384超节点和Atlas 800I A2推理服务器采取了不同的优化策略。通过PD分离部署方式,有效解耦了Prefill和Decode阶段的时延约束。在框架侧,昇腾基于vLLM框架适配了多种并行策略,并通过一系列技术降低了调度开销,提升了系统性能。
在模型方面,昇腾采用了A8W8C16量化策略,针对不同机型进行差异化部署。针对CloudMatrix 384超节点,团队采用大规模EP并行部署,最终在50毫秒时延下单卡decode吞吐达到1920 Token/s。而针对Atlas 800I A2服务器,团队采用多节点互联方式部署,在100毫秒时延下单卡吞吐达到808 Tokens/s。

华为昇腾在推理框架优化、负载不均问题处理、投机推理技术工程化应用以及通信优化等方面也取得了显著成果。例如,团队设计了API Server横向扩展方案以提升框架的请求响应能力;通过动态调整专家部署与缩小通信域等技术实现动态负载均衡;提出FusionSpec投机推理引擎优化多Token预测场景下的推理性能;以及推出FlashComm通信方案降低通信时延等。

最终,华为昇腾在Decode性能测试和Prefill测试上均取得了优异成绩。在Decode性能测试中,Atlas 800I A2在序列长度为2K输入+2K输出和1K输入+2K输出两种情况下,TPOT(Decode平均每Token时延)不超过100ms。而在Prefill测试中,对于序列长度是2K、共8 batch拼成16K序列的场景,端到端耗时为631ms,卡均吞吐为1622 Tokens/s。

硅基流动联合华为云已基于CloudMatrix 384超节点昇腾云服务和高性能推理框架SiliconLLM正式上线DeepSeek-R1服务。该服务在保证单用户20 TPS(等效50ms时延约束)水平的前提下,单卡Decode吞吐突破1920 Tokens/s,性能堪比H100部署。